Engineering • 7 min read

By Vladimír Vráb
06.11.2025
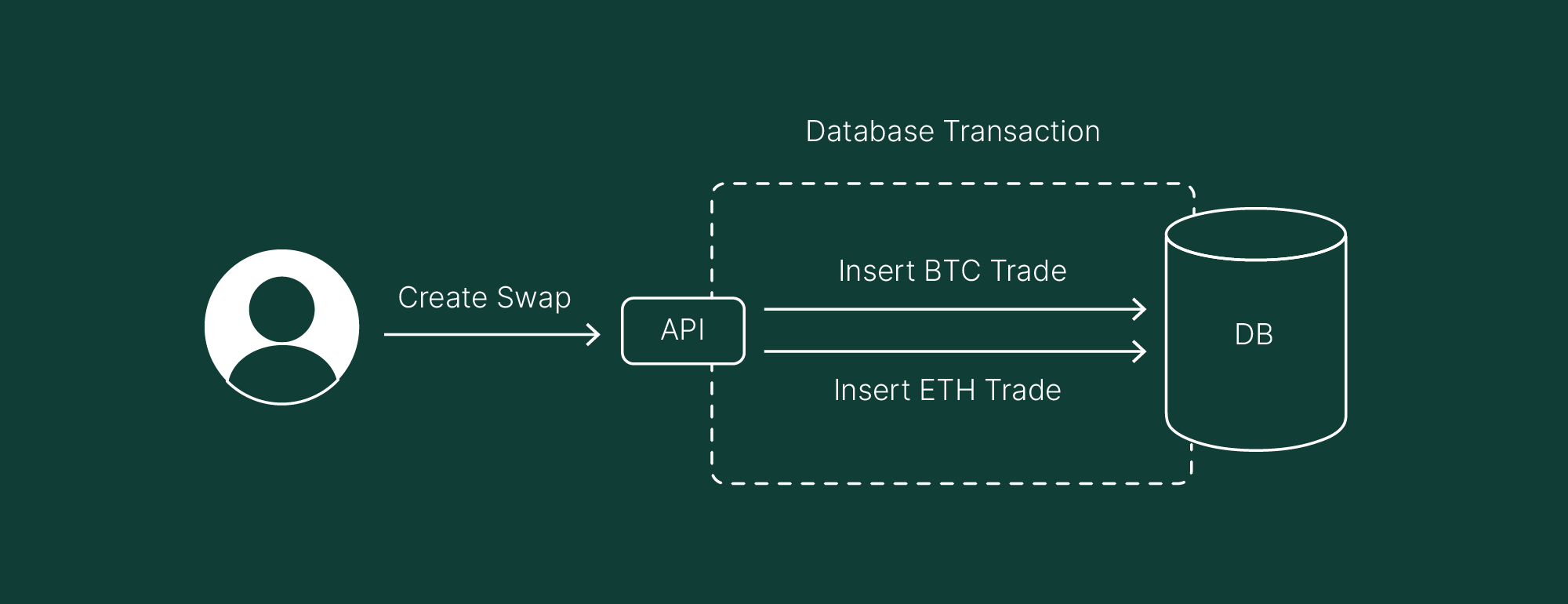
The more complex the product, the more important it is for the underlying system to be complete and consistent once the data is stored. Imagine a business requirement stating: when action A is executed, actions B and C must also be performed. If one of them fails, we definitely don’t want to end up with only action A committed to the system. Sound familiar?
At Bitpanda, this has been part of daily reality since I joined more than seven years ago. Back then, achieving such atomicity*was simpler, mainly because most of our features lived in a single monolithic application.
*Atomicity is one of the core properties of transactions in computer systems. It ensures that a series of operations either all succeed together or none happen at all—there’s no in-between state.*
In 2019, when we designed the Swaps feature, our main concern was ensuring atomic operations. Specifically, if a user swapped Bitcoin for Ethereum, the transaction had to either fully complete (sell Bitcoin and provide Ethereum) or entirely fail, without any partial outcomes. This meant preventing scenarios where a user might lose Bitcoin without receiving Ethereum, or vice versa.
Implementing this in a monolithic application with a single database was relatively simple. By opening a database transaction, the database engine (if supported) inherently provides the necessary atomic guarantees.
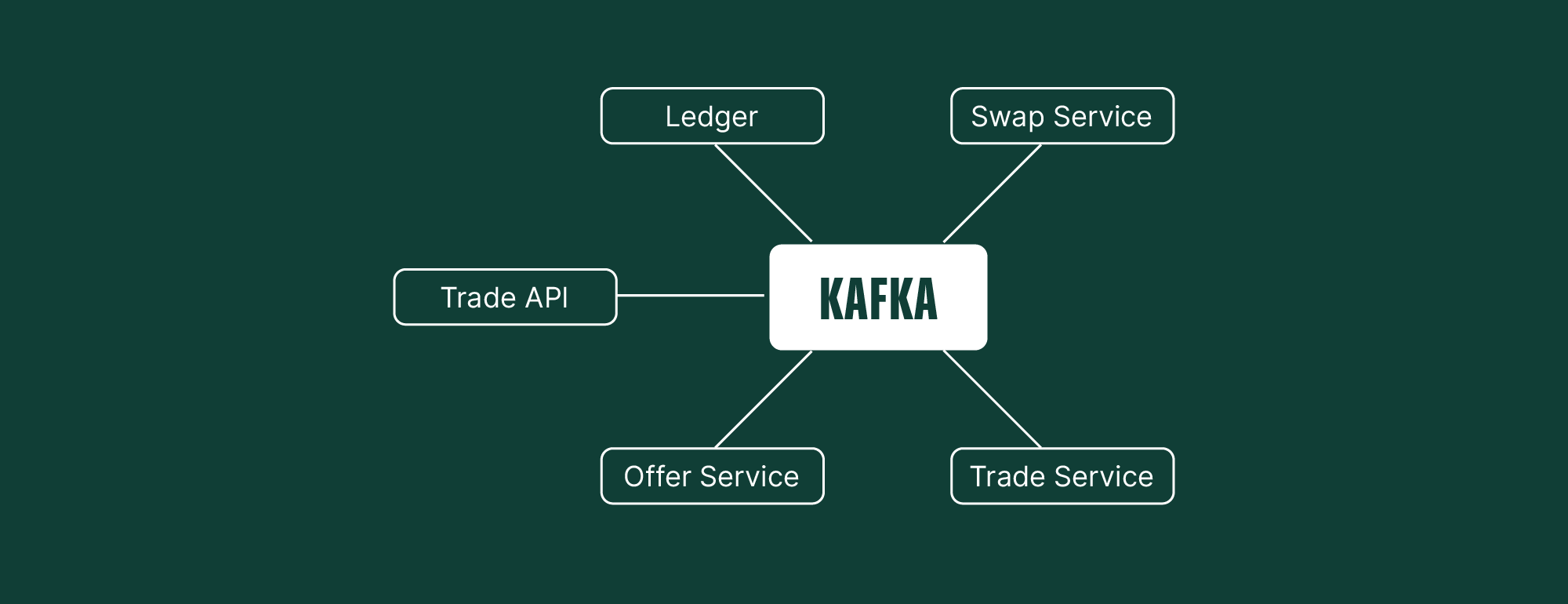
As we explained in Part #1, that approach is no longer viable. We have segmented the trading functionality into several distinct services, each with a specific role:
These services do not communicate via REST API; instead, they use Kafka, an asynchronous messaging system.
Using our previous swap example, we will demonstrate the initial system problem and our solution. This illustrates the evolution and benefits of our refined strategy.
The sequence diagram below shows our initial implementation plan.
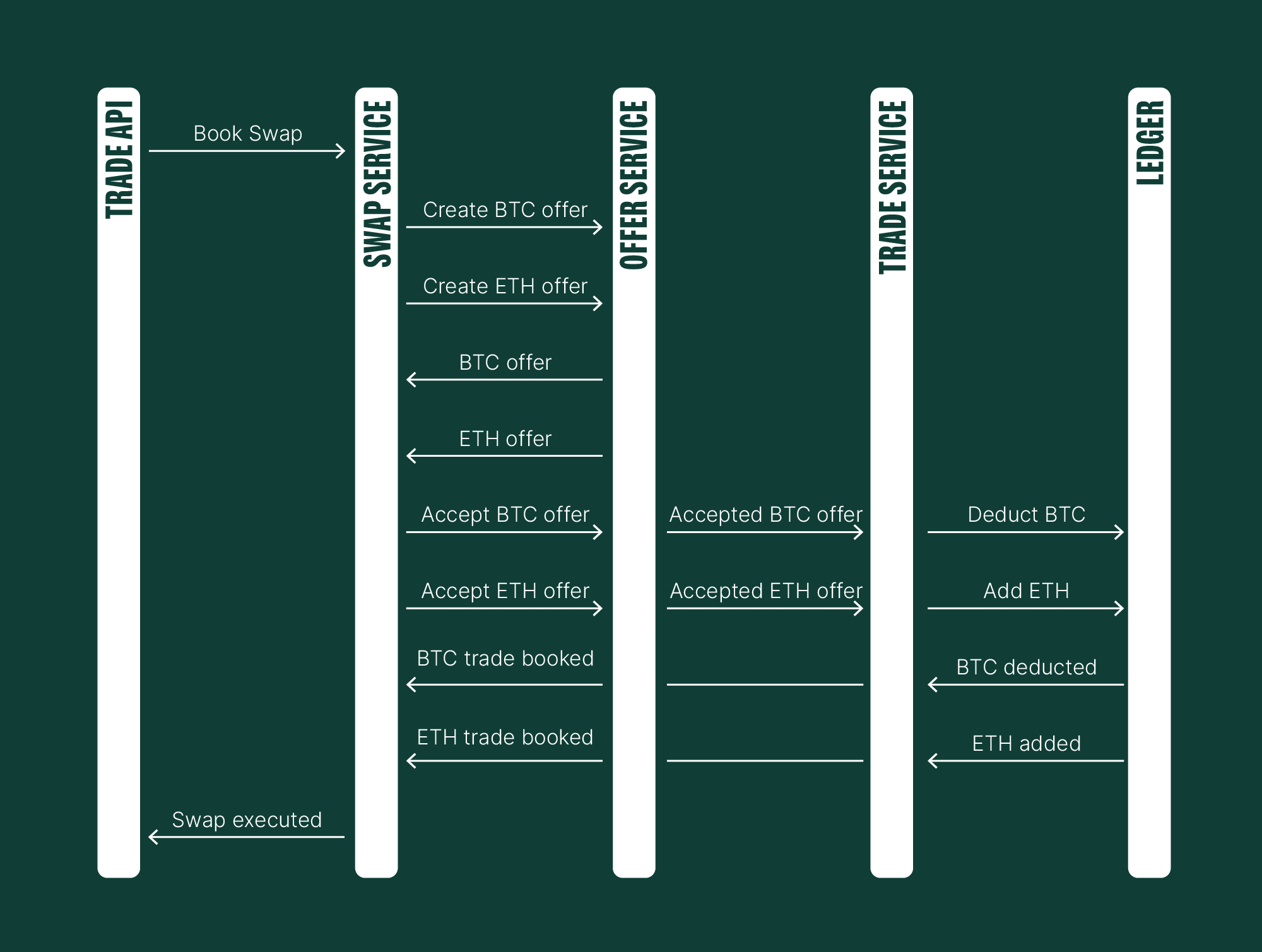
Here's a breakdown of the desired interactions:
In a real-world scenario, complications will arise, such as unreliable network connectivity or unforeseen implementation flaws.
Consider this hypothetical situation: The Ledger receives a command from Kafka to sell Bitcoin, immediately followed by a command to buy Ethereum. However, a transient network failure prevents it from connecting to the database. Consequently, an "error" occurs, resulting in a failed request.
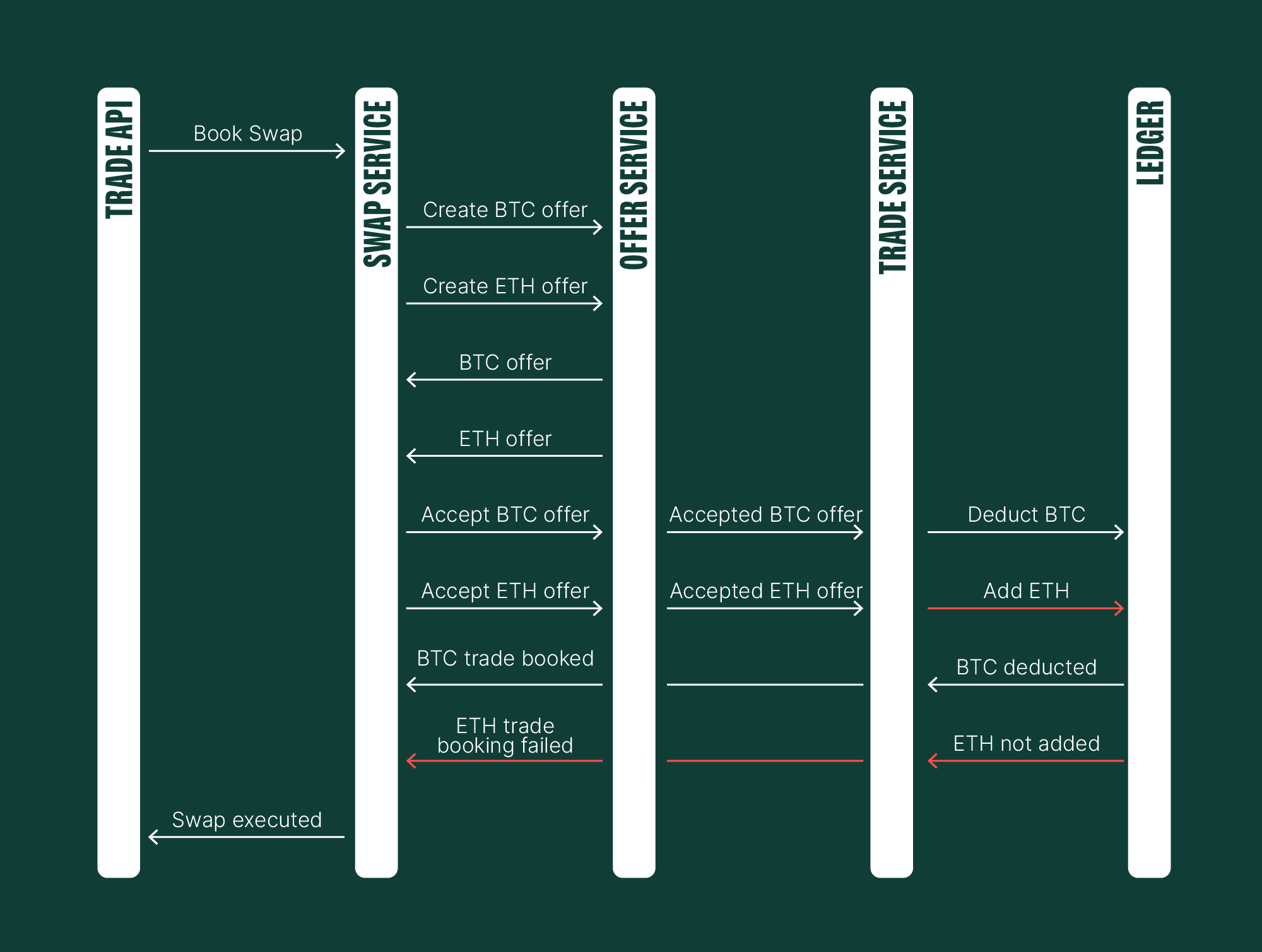
If a user sold their Bitcoin but doesn't receive Ethereum, they would be left clueless as to when their Ethereum will arrive (if it does at all!). This scenario would then violate the system constraint - every swap must have both a source and a target trade.
To address this, we need a solution. A potential quick improvement involves adding retry functionality to the Swap Service. Upon receiving an event indicating a failed Ethereum transaction booking, the system would automatically attempt to book the trade again.
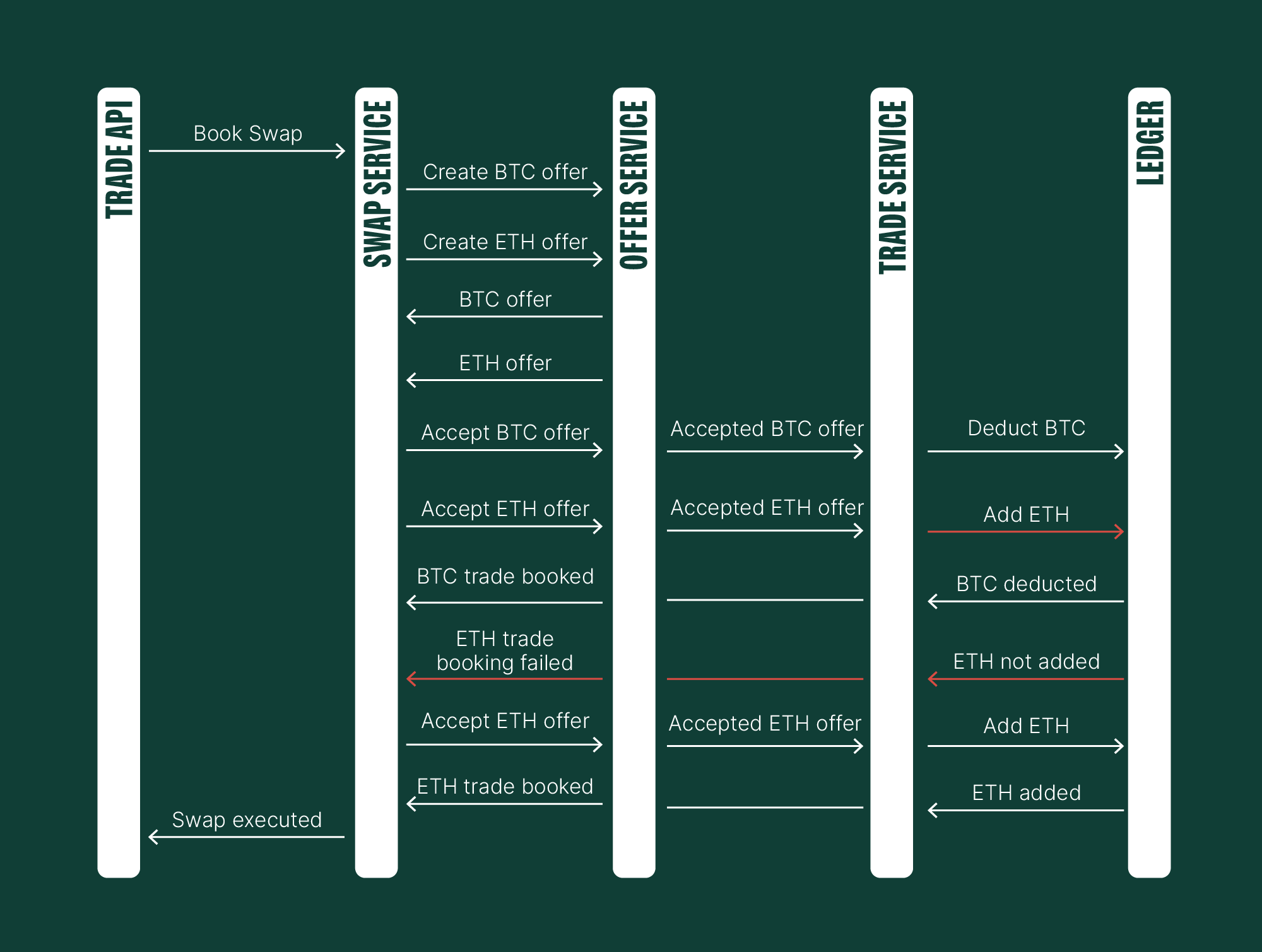
While this system is pretty solid, it does have a few limitations. A major one is that offers have an expiration time. If you don't accept an offer within that window, it will expire, and you won't be able to accept it later. This can sometimes make things a bit tricky.
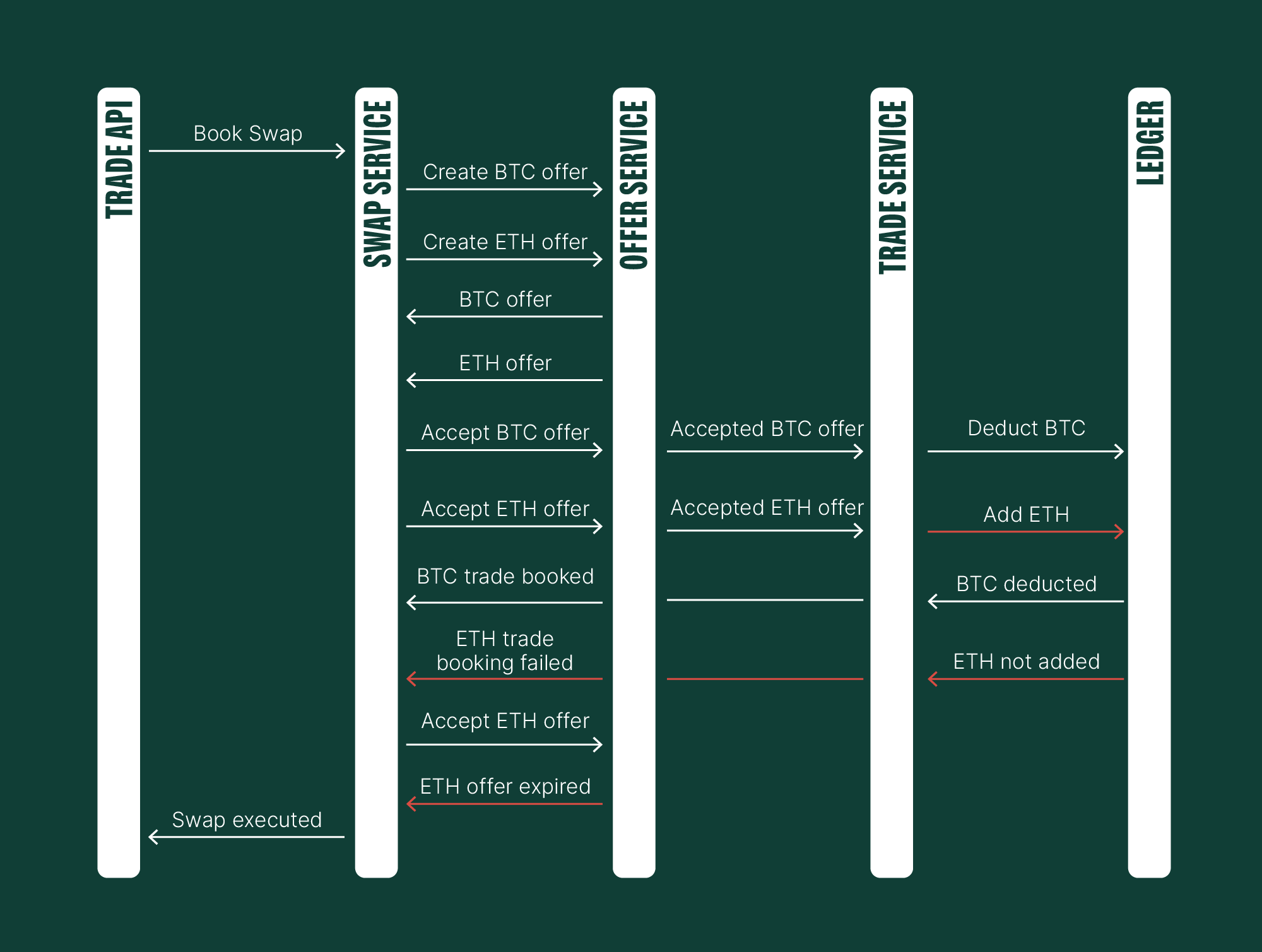
Here is a peculiar situation. We know we can’t go forward anymore. So, what if we go backwards? What if we try to reverse the trade?
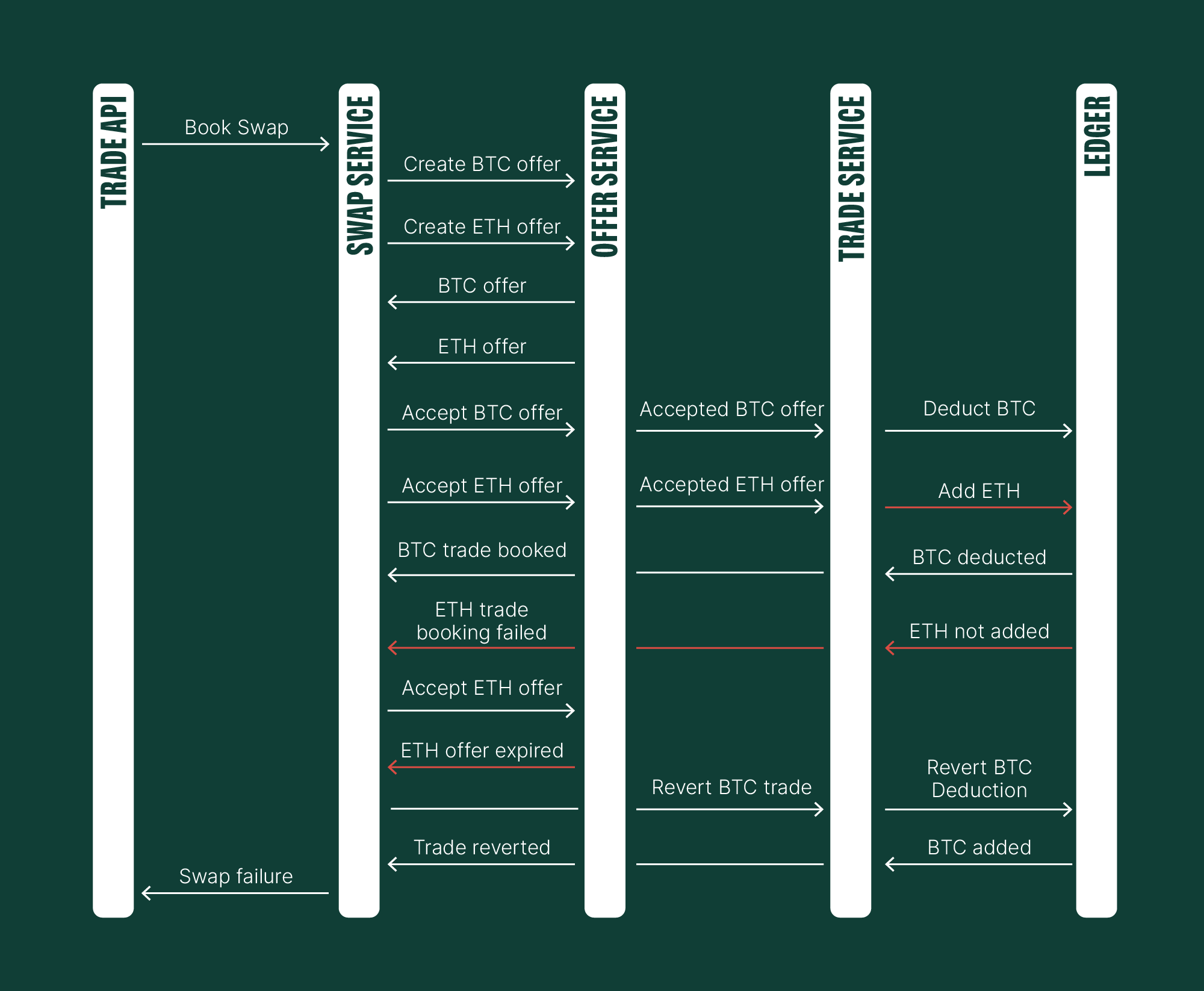
Excellent. We have successfully reversed the Bitcoin transaction on the Ledger by creating a refund transaction and reverted the trade in the Trade Service. But does this finally resolve our problem? Well, before we answer that, consider these scenarios:
What if the Ledger couldn't revert the Bitcoin transaction?
What if the Ledger is under heavy load, and a circuit breaker is rejecting most of the incoming requests?
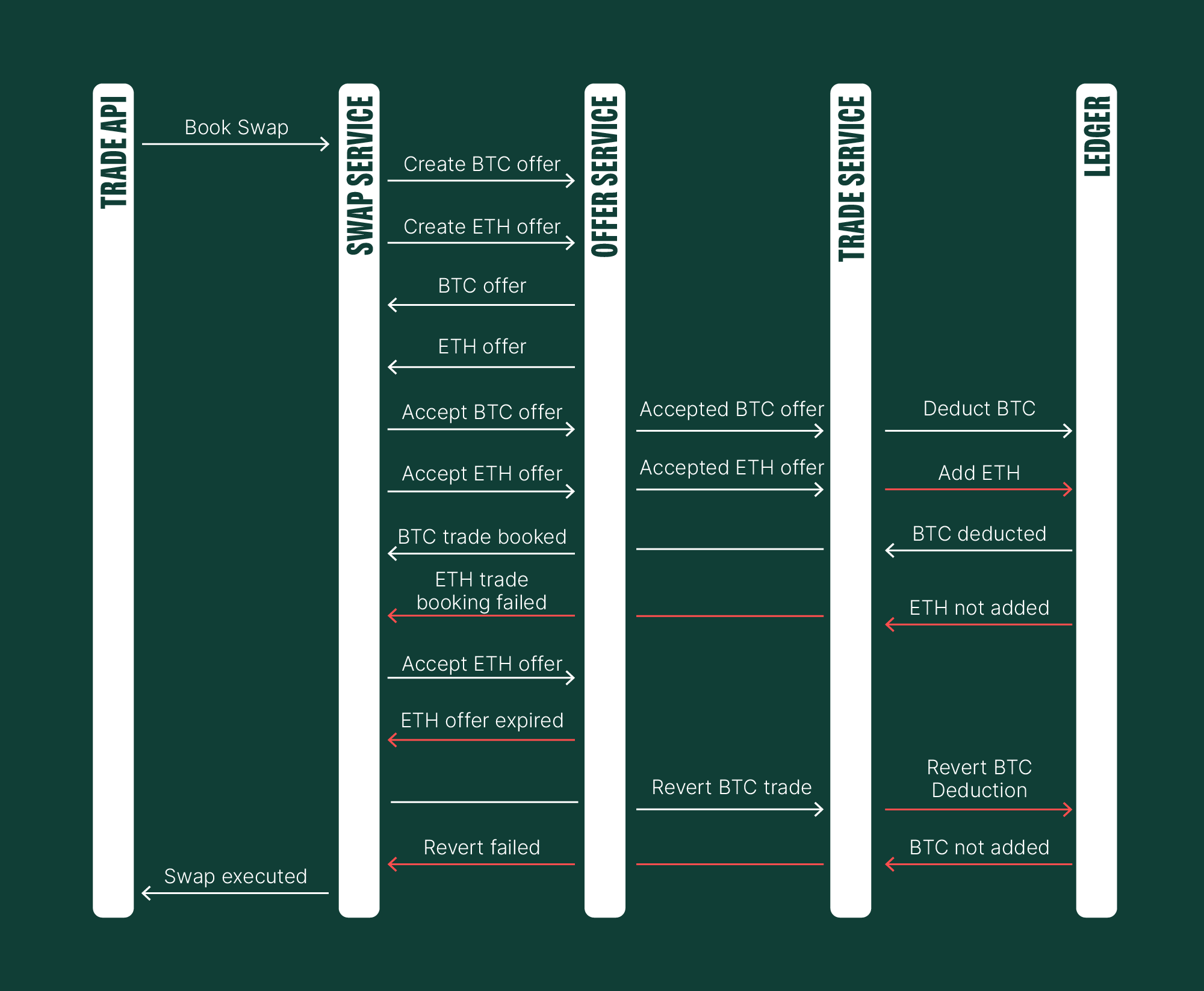
Our attempted revert failed. For instance, in a previous step, we might have relied on "retryability to the rescue." This time, however, infrastructure disruptions prevented Ledger instances from being deployed, leaving the service unavailable for 15 minutes.
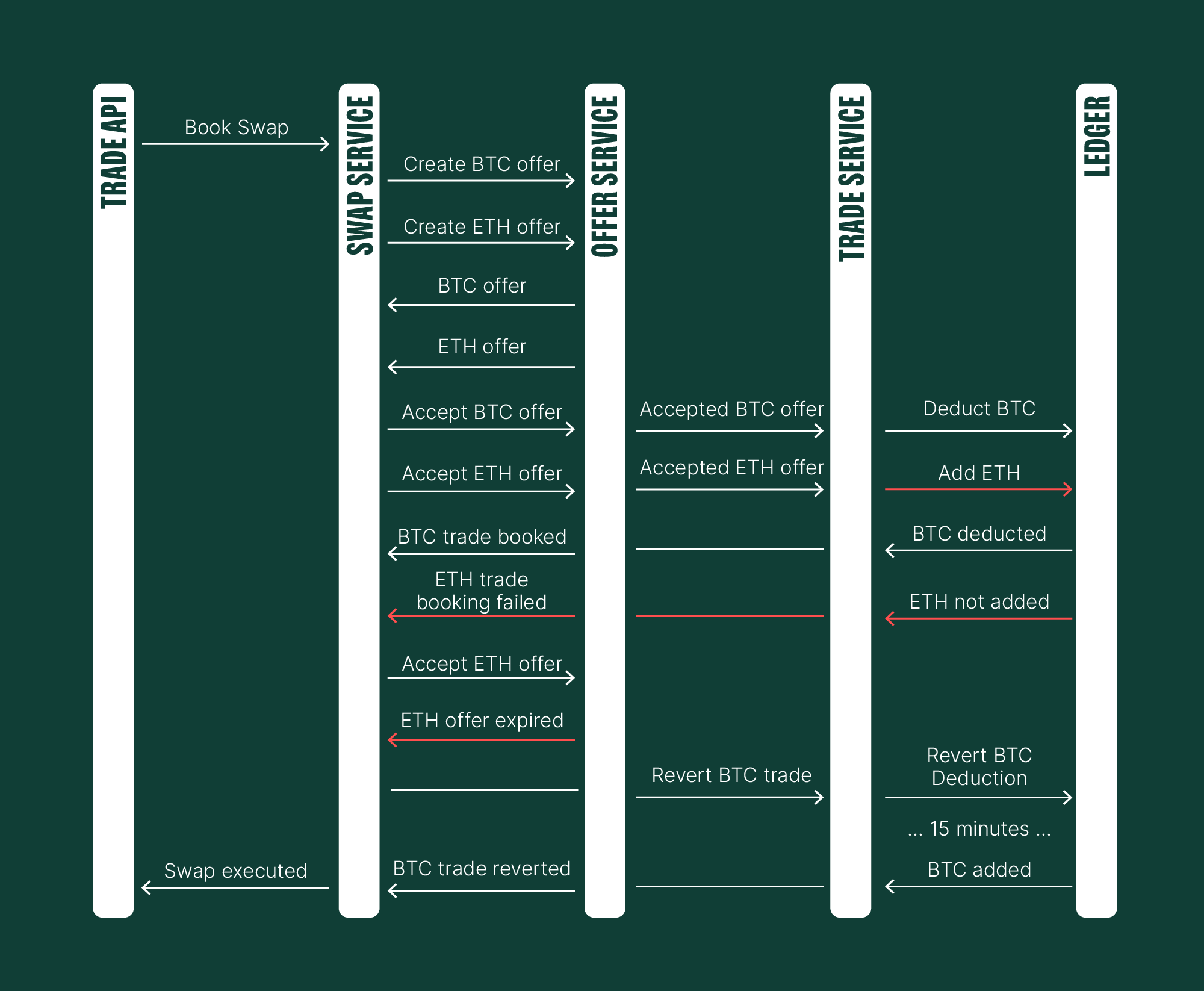
Even though the Ledger came online, processed our request, and successfully reverted the BTC transaction (and Trade Service reverted the trade), this architecture isn't viable for our operations. When a user sells Bitcoin, it triggers a hedging operation on our end. If we then need to reverse this hedging operation (and buy back Bitcoin) within 15 minutes, there's a non-zero probability that the price will have worsened, leading to financial loss. This is because we must return the same amount the user initially tried to swap.
Similarly, financial losses would occur if we successfully added Ethereum to the user's balance but failed to deduct Bitcoin. The user could spend these funds in the interim, creating an unpleasant situation for both parties. Beyond financial risks, consider the implications if the user exported their trading activity during this period.
This illustrates just some of the potential side effects of such an architecture. Therefore, we require a different, though not necessarily complex, solution.
We ensure that all trade transactions are saved completely, thanks to a coordinated custom "saga" system.
The term “saga” might be confusing. Let’s clarify: it is simply an internal name for our custom solution. In contrast, the common “saga pattern” refers to a strategy in which multiple transactions are processed, and if any fail, compensating transactions are executed to maintain consistency.
Here's how it works: When we get a request to book a transaction, it can include a saga-context header. If it does, we know that this transaction is just one piece of a larger puzzle, and we won't actually book it until we've received all the other related parts.
The saga-context header contains the following attributes:
Here's a quick look at the Bitcoin to Ethereum swap sequence diagram using our custom saga implementation:
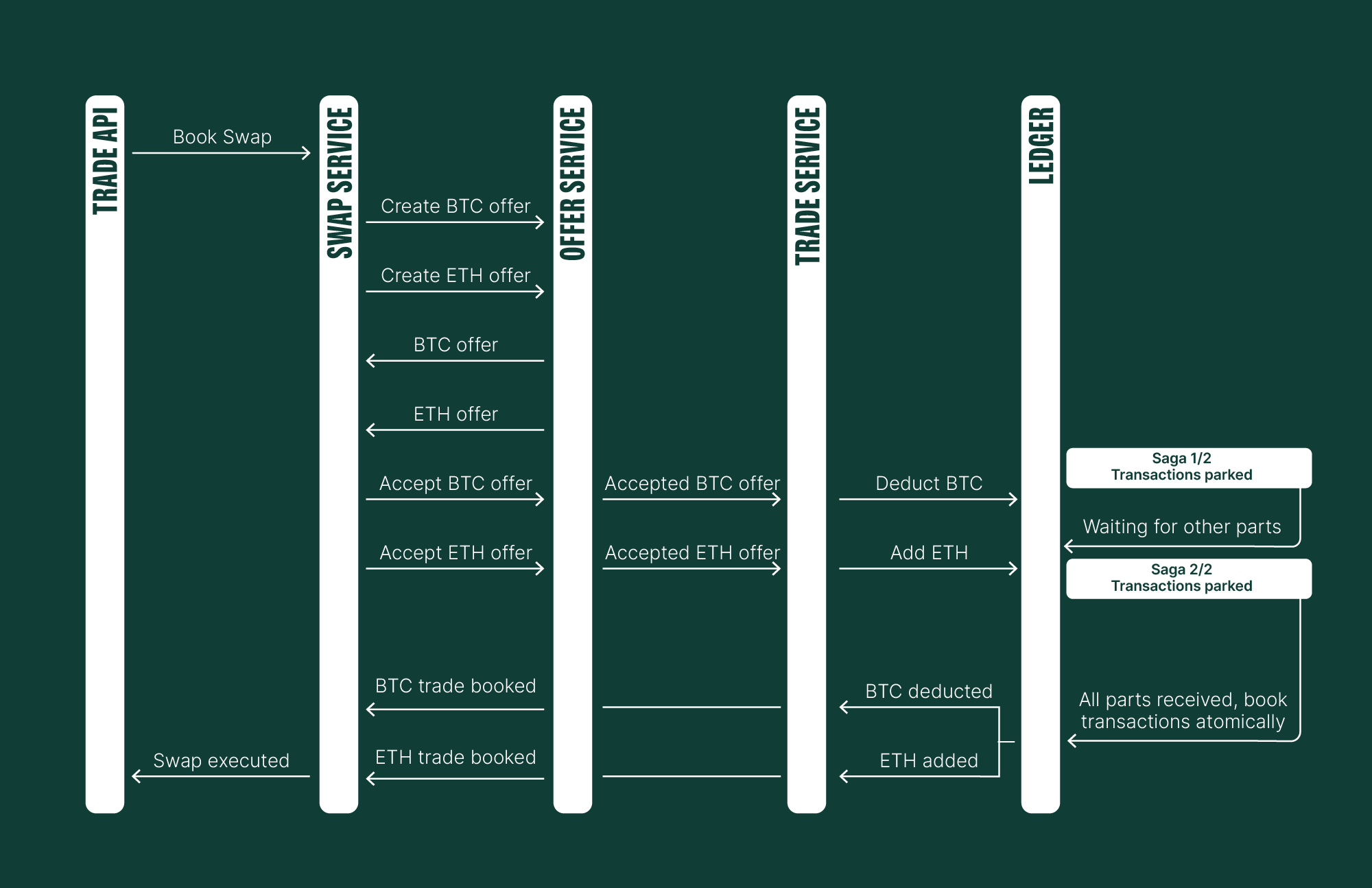
We've confirmed the successful execution of a straightforward transaction path. Now, we'll simulate scenarios where transactions cannot be booked, without going into every possible negative outcome. If, for any reason, we're unable to book transactions, both commands will fail.
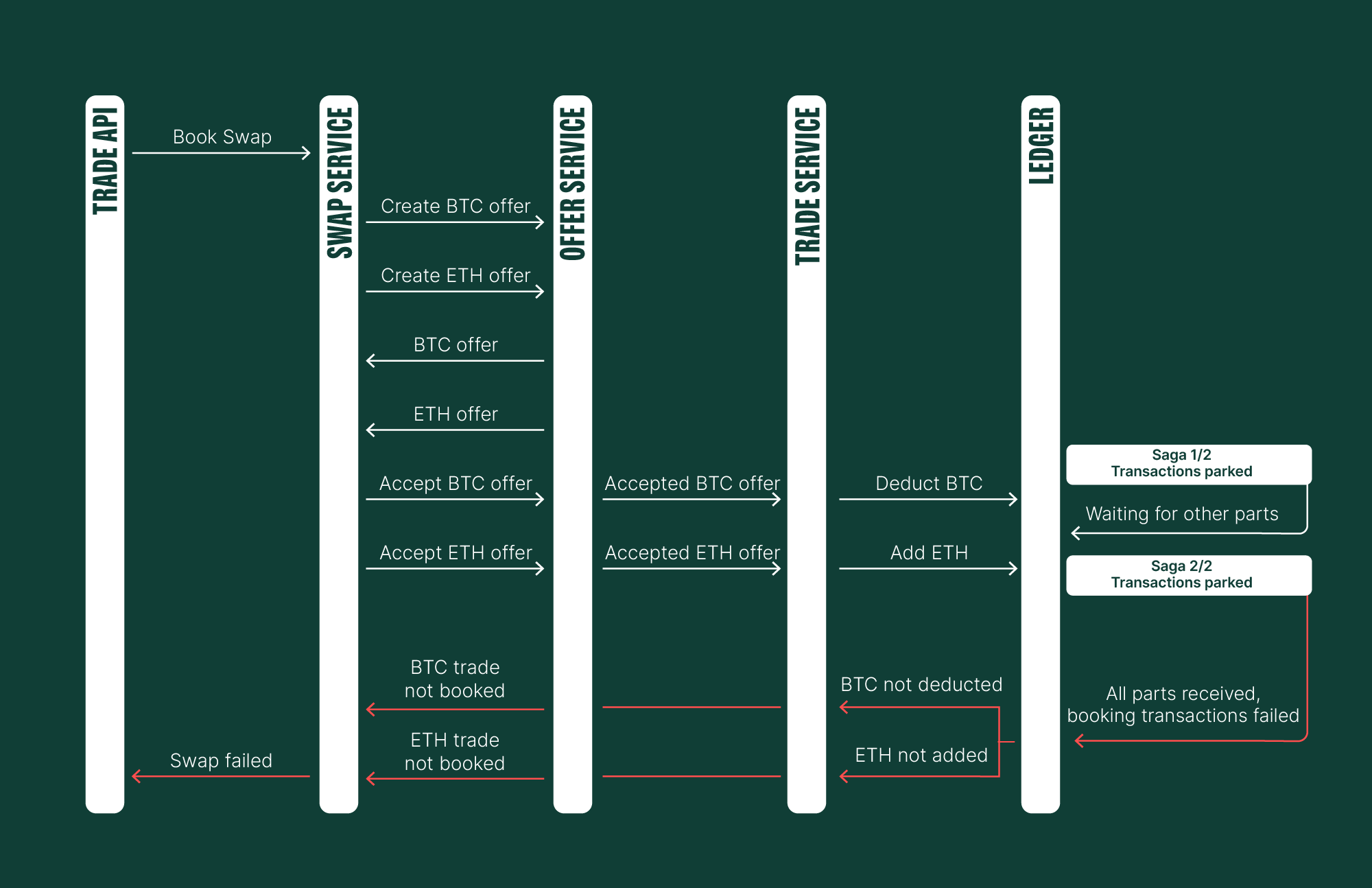
This straightforward mechanism is generic and adaptable, and not specifically designed for our use case. Other teams can easily adopt this feature by simply appending the saga context to Kafka commands. A key benefit is that there's no limit to the number of saga parts.
We've explored distributed transactions, a crucial concept for anyone developing complex distributed systems. These transactions are essential when a component receives inputs from various sources at different times, all of which must be processed atomically. While it's true that distributed transactions add to system complexity, a slim implementation with potential saga timeouts can put you on the right path.
It's tempting to attach these complexities to the decade-long shift from monolithic applications to microservices, and that's a valid point. However, every problem has multiple solutions, and careful consideration is needed when choosing one over another to ensure the benefits outweigh the drawbacks. We've reached a stage where the advantages of our distributed solutions are clear. They scale elegantly, allow for easy building upon existing solutions, and have significantly improved our overall resiliency.
We use cookies to optimise our services. Learn more
The information we collect is used by us as part of our EU-wide activities. Cookie settings
As the name would suggest, some cookies on our website are essential. They are necessary to remember your settings when using Bitpanda, (such as privacy or language settings), to protect the platform from attacks, or simply to stay logged in after you originally log in. You have the option to refuse, block or delete them, but this will significantly affect your experience using the website and not all our services will be available to you.
We use such cookies and similar technologies to collect information as users browse our website to help us better understand how it is used and then improve our services accordingly. It also helps us measure the overall performance of our website. We receive the date that this generates on an aggregated and anonymous basis. Blocking these cookies and tools does not affect the way our services work, but it does make it much harder for us to improve your experience.
These cookies are used to provide you with adverts relevant to Bitpanda. The tools for this are usually provided by third parties. With the help of these cookies and such third parties, we can ensure for example, that you don’t see the same ad more than once and that the advertisements are tailored to your interests. We can also use these technologies to measure the success of our marketing campaigns. Blocking these cookies and similar technologies does not generally affect the way our services work. Please note, however, that while you’ll still see advertisements about Bitpanda on websites, the adverts will no longer be personalised for you.



